准备工作
时间机器备份
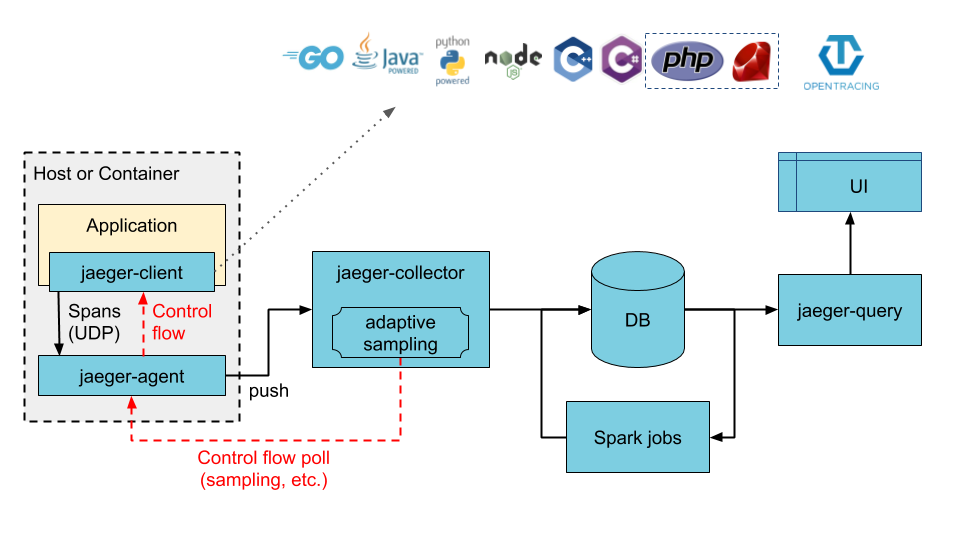
使用“时间机器”备份您的 Mac,按照官方指导一步一步来就可以了。这里要特别强调一点,在备份的时候务必确认一下这里:
 第一次备份的时候没注意,导致没有按需备份所需资料,后面重新备份恢复浪费大把时间。
第一次备份的时候没注意,导致没有按需备份所需资料,后面重新备份恢复浪费大把时间。U盘启动盘
转接卡
上篇文章提过,mac的硬盘接口不是标准的m.2,必须得弄一个转接卡,这个万能的宝上有比较多,关键字:“m.2 转 苹果”,价格15~30之间,我选择了一个开了10年的店铺,但是非要两个包邮,想着也不算太贵,就直接拍了,在这个特殊情况下竟然只花了1天半时间就到手了,竟然比正常时候都快。之前看网上的文章,有说这个卡看运气,运气不好长了或者短了或者兼容性不好,那就尴尬了,我这次还算运气好,大小很合适,兼容性也没问题。
 非常小巧
非常小巧螺丝刀
mac背面的几个螺丝非常小,需要特殊的螺丝刀,这个我在某东上买的,比较亏,建议在某宝上买,10块钱应该可以搞定。除了后背螺丝外,拆解硬盘的时候还需要一个不一样的螺丝刀,如下图:
 其中1.2上用于拆后盖螺丝,t5拆解硬盘。
其中1.2上用于拆后盖螺丝,t5拆解硬盘。新固态硬盘
由于最近疫情原因,ssd涨价非常多,一直在intel760p和三星970evo中纠结,本着这两个都是网友们推荐的兼容性较好的,而且我的本本也都不跑满这些新硬件的性能,选择的依据就是性价比了。在我出手时这两个一直都是100的差价,当转接卡到手后准备下手760的时候,不知道店家干啥的突然涨价100,估计是被大数据杀熟了(我添加了这几款ssd在购物车了),刚好三星那边又搞活动降价了一点点,这么一看那970毫不犹豫了,毕竟原装的也是三星的,性能相对也更好。

拆机
关闭电源!!!
拆后背螺丝
这个比较简单,拿1.2螺丝刀挨个弄下里就行了,唯一需要注意的是键盘部位中间的两个螺丝跟其他螺丝相比稍短,不然找起来比较麻烦。
拔下电池,这个非常重要!!!


硬盘更换
这个步骤需要用到t5螺丝刀
- 拆下原装硬盘螺丝
- 拔下硬盘
- 插上转接卡
- 插上新硬盘
- 撞上螺丝
硬盘换上之后,记得把电池插口还原,此时可以把后盖盖上,但是先不要上螺丝,以免遇到各种不兼容问题导致电脑无法点亮。
新硬盘系统安装
插上u盘启动盘,打开电源开关,此时会进到macos的恢复模式,首选需要进行新硬盘的格式化。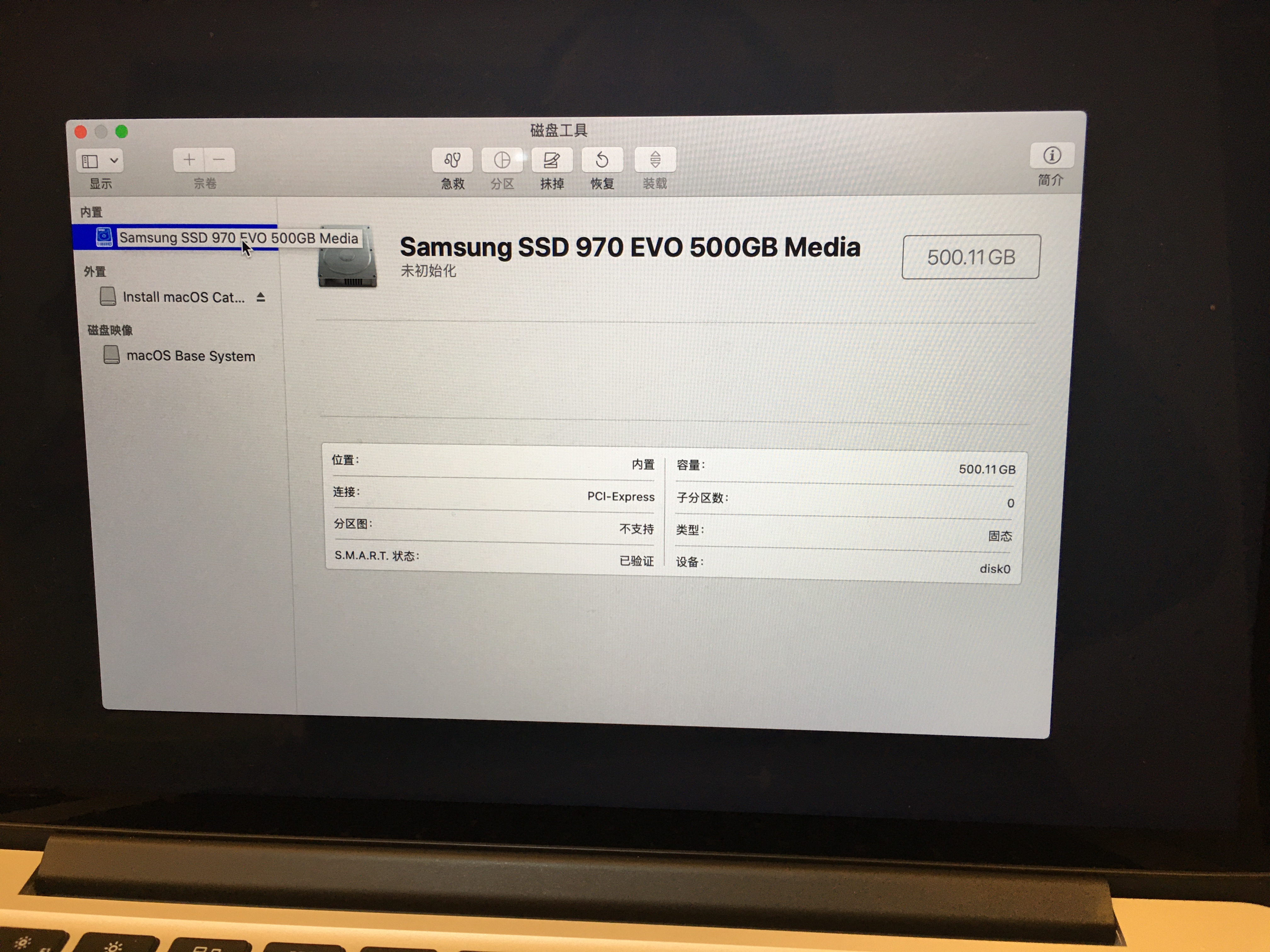
关于硬盘格式的选择网上大部分都是建议选择Mac OS 扩展(日志式)+ GUID分区,其实官方也有相应的文档说明:在 APFS 和 Mac OS 扩展格式之间进行选择。我直接用的APFS格式,后面也没遇到啥问题,格式化之后,又回回到使用工具界面: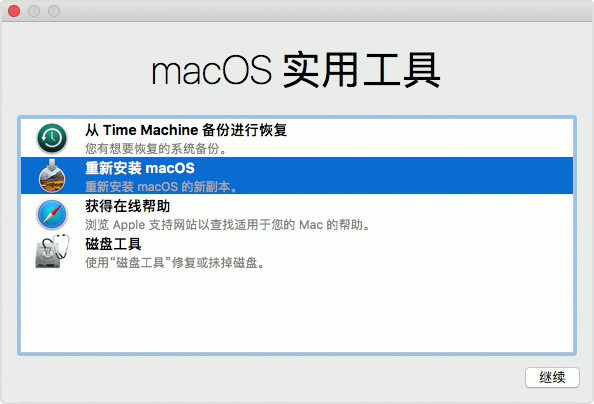
这次选择重新安装macos,按照提示来就好了。
恢复原硬盘备份
上面的系统安装完成后,会进行一系列的设置等操作,后面会进到迁移助理界面,这个就需要用到前面提到的时间机器备份了,官方也有很详细的描述。
从备份恢复 Mac。我第一次恢复之后,进入系统发现很多应用没有了,部分目录也不见了,当时觉得很奇怪,难道是时间机器有bug么?期间打了一次苹果的技术支持电话,详细说明了情况,可惜那个顾问也没能给到有效解释,只是让我再备份一次。
我只好再把硬盘来回倒腾了一番,装上了原来的,再次进入时间机器,我猛然看到一个前面第一幅图,然来是有些备份被排除了,很奇怪的是官方的文档也没强调这一点。再次按需备份之后,进入新硬盘系统,时间机器里面也能看到最新的一次备份,但是就是没法进行恢复(按钮颜色都不一样)。
但是因为有时间机器,我打算干脆重新装一次再恢复得了,进入恢复模式的实用工具之后,点击从TimeMachine恢复,里面就可以看到最新的备份,而且也提示会直接把系统也一起抹掉恢复,最后总算是顺利完成。
最后来两张性能对比: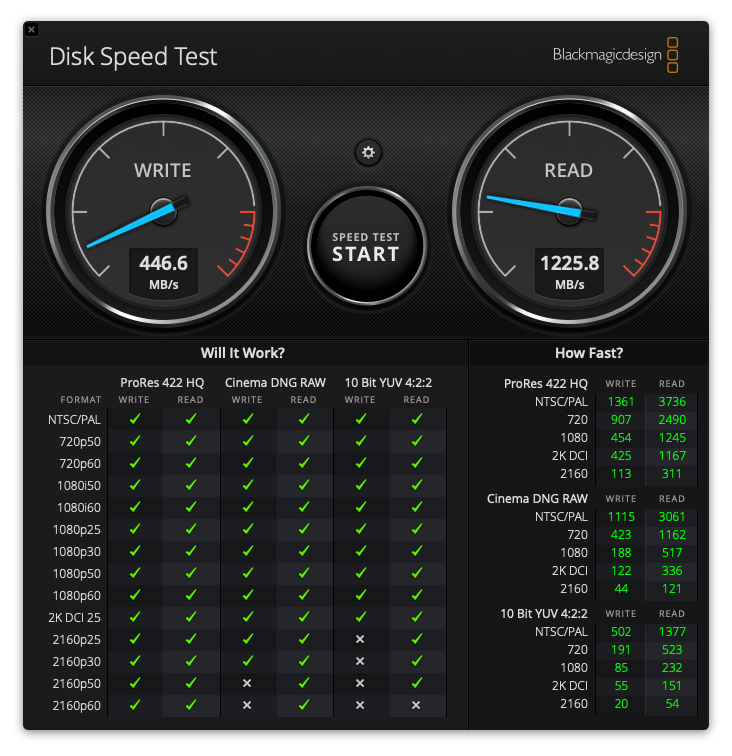
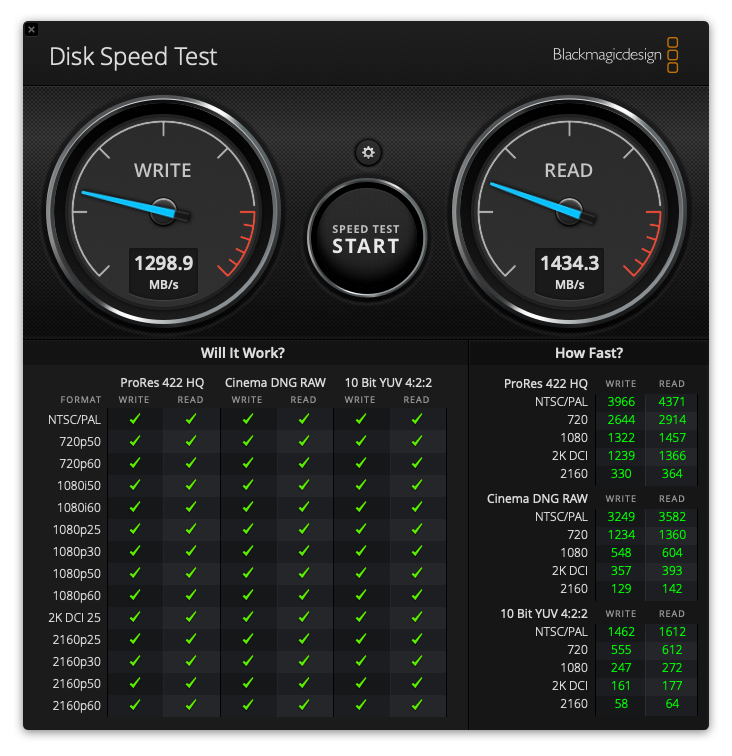
读性能基本上没啥区别,写提高近三倍,跟官方标榜的读2300 MB/s 和 写3400 MB/s差距还不小,当然这个主要是2015款mbp的物理接口限制了。
总结
mac换硬盘这个事情,其实从预谋到实施也就两周,期间主要是新硬盘选择和准备工具花了不少时间。真正换硬盘的时间反而是最微不足道的,备份数据和恢复数据花了95%的时间,最终新的硬盘果然也是没法最大程度释放硬件能力,不过我的初衷是扩大容量,这么来看也算符合预期了。