- 第一阶段,刚接触Blog,觉得很新鲜,试着选择一个免费空间来写。
- 第二阶段,发现免费空间限制太多,就自己购买域名和空间,搭建独立博客。
- 第三阶段,觉得独立博客的管理太麻烦,最好在保留控制权的前提下,让别人来管,自己只负责写文章。
上面这段换摘抄自阮一峰的博客,有一种似曾相识的感觉:
- 编程爱好者博客
- 百度Hi空间
- CSDN
- 虚拟空间
- 域名+虚拟空间
- 域名+VPS
- GitHub Pages+Hexo。
上面这段换摘抄自阮一峰的博客,有一种似曾相识的感觉:
这个问题看了很多次,忘了很多次,最近在重温内存池时又看了下,做个笔记吧。
首先是两个名词:new表达式,new操作符,
默认情况下当你写下如下语句时:
Foo* foo = new Foo;(这里是new-expression),实际执行了三个步骤:
1:new表达式调用一个operator new的标准库函数,分配一块足够大、原始的、未命名的内存空间
2:编译器运行相应的构造函数,并传入初始值
3:对象分配空间并构造完成,返回一个指向该对象的指针
delete foo,实际执行了两个相反的步骤:
1:调用该对象的析构函数
2:调用operator delete标准库函数,回收空间
c++中new/delete有如下级别:
class specific new/delete
通过代码来说明问题比较直观
重载全局操作符
#include <iostream>
#include <stdlib.h>
class Foo
{
public:
Foo()
{
std::cout << FUNCTION << std::endl;
}
~Foo()
{
std::cout << FUNCTION << std::endl;
}
};
//重载全局new操作符,和一般的操作符重载类似
void operator new(size_t sz)
{
std::cout << FUNCTION << std::endl;
void m = malloc(sz);
if(!m)
{
std::cerr << “out of memory” << std::endl;
}
return m;
}
//重载全局delete操作符,和一般的操作符重载类似
void operator delete(void* m)
{
std::cout << FUNCTION << std::endl;
free(m);
}
int main(int argc, const char argv[])
{
//new-expression(表达式)
//首先调用全局的operator(操作符) new分配内存,再调用构造函数
Foo foo = new Foo;
//delete-expression
//首先调用析构函数,再调用全局的operator(操作符) delete释放内存
delete foo;
return 0;
}
#include <cstddef>
#include <iostream>
#include <new>
class Framis
{
enum { sz = 10 };
char c[sz]; // To take up space, not used
static unsigned char pool[];
static bool alloc_map[];
public:
enum { psize = 100 }; // frami allowed
Framis() { std::cout << FUNCTION << std::endl; }
~Framis() { std::cout << FUNCTION << std::endl; }
void operator new(size_t) throw(std::bad_alloc);
void operator delete(void);
};
unsigned char Framis::pool[psize * sizeof(Framis)];
bool Framis::alloc_map[psize] = {false};
// Size is ignored – assume a Framis object
void Framis::operator new(size_t) throw(std::bad_alloc)
{
for(int i = 0; i < psize; i++)
{
if(!alloc_map[i])
{
std::cout << “using block “ << i << “ … “;
alloc_map[i] = true; // Mark it used
return pool + (i sizeof(Framis));
}
}
std::cout << “out of memory” << std::endl;
throw std::bad_alloc();
}
void Framis::operator delete(void* m)
{
if(!m) return; // Check for null pointer
// Assume it was created in the pool
// Calculate which block number it is:
unsigned long block = (unsigned long)m - (unsigned long)pool;
block /= sizeof(Framis);
std::cout << “freeing block “ << block << std::endl;
// Mark it free:
alloc_map[block] = false;
}
int main()
{
Framis f[Framis::psize];
try
{
for(int i = 0; i < Framis::psize; i++)
{
f[i] = new Framis;
}
new Framis; // std::cout of memory
}
catch(std::bad_alloc)
{
std::cerr << “out of memory!” << std::endl;
}
delete f[10];
f[10] = 0;
// Use released memory:
Framis x = new Framis;
delete x;
for(int j = 0; j < Framis::psize; j++)
{
delete f[j]; // Delete f[10] OK
}
return 0;
}
上面的例子是从<<think in c++>>中copy过来的,类的new/delete操作符函数,尽管你可以不写static关键字,但是编译器其实把其当做static函数的。
另外还有个叫做placement new/delete表达式的重载,可以在指定的地址空间上构造/析构对象。
What is important to keep in mind when you are designing a distributed system?
We should start off with some notion of what we mean by distributed system. A distributed system, in the sense in which I take any interest, means a system in which the failure of an unknown computer can screw you.
Failure is not such an important factor for some multicomponent distributed systems. Those systems are tightly controlled; nobody ever adds anything unexpectedly; they are designed so that all components go up and down at the same time. You can create systems like that, but those systems are relatively uninteresting. They are also quite rare.
Failure is the defining difference between distributed and local programming, so you have to design distributed systems with the expectation of failure. Imagine asking people, “If the probability of something happening is one in ten to the thirteenth, how often would it happen?” Your natural human sense would be to answer, “Never.” That is an infinitely large number in human terms. But if you ask a physicist, she would say, “All the time. In a cubic foot of air, those things happen all the time.” When you design distributed systems, you have to say, “Failure happens all the time.” So when you design, you design for failure. It is your number one concern.
Yes, you have to get done what you have to get done, but you have to do it in the context of failure. One reason it is easier to write systems with Jini and RMI (remote method invocation) is because they’ve taken the notion of failure so seriously. We gave up on the idea of local/remote transparency. It’s a nice thought, but so is instantaneous faster-than-light travel. It is demonstrably true that at least so far transparency is not possible.
What does designing for failure mean? One classic problem is partial failure. If I send a message to you and then a network failure occurs, there are two possible outcomes. One is that the message got to you, and then the network broke, and I just couldn’t get the response. The other is the message never got to you because the network broke before it arrived. So if I never receive a response, how do I know which of those two results happened? I cannot determine that without eventually finding you. The network has to be repaired or you have to come up, because maybe what happened was not a network failure but you died.
Now this is not a question you ask in local programming. You invoke a method and an object. You don’t ask, “Did it get there?” The question doesn’t make any sense. But it is the question of distributed computing.
So considering the fact that I can invoke a method on you and not know if it arrives, how does that change how I design things? For one thing, it puts a multiplier on the value of simplicity. The more things I can do with you, the more things I have to think about recovering from. That also means the conceptual cost of having more functionality has a big multiplier. In my nightmares, I’ll tell you it’s exponential, and not merely a multiplier. Because now I have to ask, “What is the recovery strategy for everything on which I interact with you?” That also implies that you want a limited number of possible recovery strategies.
So what are those recovery strategies? J2EE (Java 2 Platform, Enterprise Edition) and many distributed systems use transactions. Transactions say, “I don’t know if you received it, so I am forcing the system to act as if you didn’t.” I will abort the transaction. Then if you are down, you’ll come up a week from now and you’ll be told, “Forget about that. It never happened.” And you will.
Transactions are easy to understand: I don’t know if things failed, so I make sure they failed and I start over again. That is a legitimate, straightforward way to deal with failure. It is not a cheap way however.
Transactions tend to require multiple players, usually at least one more player than the number of transaction participants, including the client. And even if you can optimize out the extra player, there are still more messages that say, “Am I ready to go forward? Do you want to go forward? Do you think we should go forward? Yes? Then I think it’s time to go forward.” All of those messages have to happen.
And even with a two-phase commit, there are some small windows that can leave you in ambiguous states. A human being eventually has to interrupt and say, “You know, that thing did go away and it’s never coming back. So don’t wait.” Say you have three participants in a transaction. Two of them agree to go forward and are waiting to be told to go. But the third one crashes at an inopportune time before it has a chance to vote, so the first two are stuck. There is a small window there. I think it has been proven that it doesn’t matter how many phases you add, you can’t make that window go away. You can only narrow it slightly.
So the transactions approach isn’t perfect, although those kinds of problems happen rarely enough. Maybe instead of ten to the thirteenth, the probability is ten to the thirtieth. Maybe you can ignore it, I don’t know. But that window is certainly a worry.
The main point about transactions is that it has overhead. You have to create the transaction and you have to abort it. One of the things that a container like J2EE does for you is that it hides a lot of that from you. Most things just know that there’s a transaction around them. If somebody thinks it should be aborted, it will be aborted. But most things don’t have to participate very directly in aborting the transaction. That makes it simpler.
I tend to prefer something called idempotency. You can’t solve all problems with it, but basically idempotency says that reinvoking the method will be harmless. It will give you an equivalent result as having invoked it once.
If I want to manipulate a bank account, I send in an operation ID: “This is operation number 75. Please deduct $100 from this bank account.” If I get a failure, I just keep sending it until it gets through. If you’re the recipient, you say, “Oh, 75. I’ve seen that one, so I’ll ignore it.” It is a simple way to deal with partial failure. Basically, recovery is simple retry. Or, potentially, you give up by sending a cancel operation for the ID until that gets through. If you want to do that, though, you’re more likely to use transactions so you can abort them.
Generally, with idempotency, everybody needs to know how to go forward. But people don’t often need to know how to go back. I don’t abort a transaction. I just repeatedly try again until I succeed. That means I need to know how to say to do this. I don’t have to deal with all sorts of ugly recovery most of the time.
Now, what happens if failure increases on the network? You start sending messages more often. If that is a problem, for a long distance you can solve it by writing a check and buying more hardware. Hardware is much cheaper than programmers. Other ways of dealing with this tend to increase the system’s complexity, requiring more programmers.
Do you mean transactions?
Transactions on everything can increase complexity. I’m just talking about transactions and idempotency now, but other recovery mechanisms exist.
If I just have to try everything twice, if I can simply reject the second request if something has already been done, I can just buy another computer and a better network—up to some limit, obviously. At some point, that’s no longer true. But a bigger computer is more reliable and cheaper than another programmer. I tend to like simple solutions and scaling problems that can be solved with checkbooks, even though I am a programmer myself.
Is there anything in particular about Internet- wide distributed systems or large wide area networks that is different from smaller ones? Dealing with increased latency, for example?
Yes, latency has a lot to do with it. When you design anything, local or remote, efficiency one of the things you think about. Latency is an important issue. Do you make many little calls or one big call? One of the great things about Jini is that, if you can use objects, you can present an API whose natural model underneath deals with latency by batching up requests where it can. It adapts to the latency that it is in. So you can get away from some of it, but latency is a big issue.
Another issue is of course security. Inside a corporate firewall you say, “We’ll do something straightforward, and if somebody is mucking around with it, we’ll take them to court.” But that is clearly not possible on the Internet; it is a more hostile environment. So you either have to make things not care, which is fine when you don’t care if somebody corrupts your data. Or, you better make it so they can’t corrupt your data. So aside from latency, security is the other piece to think about in widely distributed systems.
What about state?
State is hell. You need to design systems under the assumption that state is hell. Everything that can be stateless should be stateless.
Define what you mean by that.
In this sense, state is essentially something held in one place on behalf of somebody who is in another place, something that is not reconstructible by the other entity that wants it. If I can reconstruct it, it’s called a cache. And caches are often OK. Caching strategies are their own branch of computer science, and you can screw them up. But as a general rule, I send you a bunch of information and you send me the shorthand for it. I start to interact with you using this shorthand. I pass the integer back to you to refer to the cached data: “I’m talking about interaction number 17.” And then you go down. I can send that same state to some equivalent service to you, and build myself back up. That kind of state is essentially a cache.
Caching can get complex. It’s the question that Jini solves with leasing. If one of us goes down, when can the person holding the cache throw this stuff away? Leasing is a good answer to that. There are other answers, but leasing is a pretty elegant one.
On the other hand, if you store information that I can’t reconstruct, then a whole host of questions suddenly surface. One question is, “Are you now a single point of failure?” I have to talk to you now. I can’t talk to anyone else. So what happens if you go down?
To deal with that, you could be replicated. But now you have to worry about replication strategies. What if I talk to one replicant and modify some data, then I talk to another? Is that modification guaranteed to have already arrived there? What is the replication strategy? What kind of consistency do you need—tight or loose? What happens if the network gets partitioned and the replicants can’t talk to each other? Can anybody proceed?
There are answers to these questions. A whole branch of computer science is devoted to replication. But it is a nontrivial issue. You can almost always get into some state where you can’t proceed. You no longer have a single point of failure. You have reduced the probability of not being able to proceed, but you haven’t eliminated it.
If my interaction with you is stateless in the sense I’ve described—nothing more than a cache—then your failure can only slow me down if there’s an equivalent service to you. And that equivalent service can come up after you go down. It doesn’t necessarily have to be there in advance for failover.
So, generally, state introduces a whole host of problems and complications. People have solved them, but they are hell. So I follow the rule: make everything you can stateless. If there is one piece of the system you can’t make stateless—it has to have state—to the extent possible make it hold all the state. Have as few stateful components as you can.
If you end up with a system of five components and two of them have state, ask yourself if only one can have state. Because, assuming all components are critical, if either of the two stateful components goes down you are screwed. So you might as well have just one stateful component. Then at least four, instead of three, components have this wonderful feature of robustability. There are limits to how hard you should try to do that. You probably don’t want to put two completely unrelated things together just for that reason. You may want to implement them in the same place. But in terms of defining the interfaces and designing the systems, you should avoid state and then make as many components as possible stateless. The best answer is to make all components stateless. It is not always achievable, but it’s always my goal.
All these databases lying around are state. On the Web, every Website has a database behind it.
Sure, the file system underneath a Website, even if it’s just HTML, is a database. And that is one case where state is necessary. How am I going to place an order with you if I don’t trust you to hold onto it? So in that case, you have to live with state hell. But a lot of work goes into that dealing with that state. If you look at the reliable, high-performance sites, that is a very nontrivial problem to solve. It is probably the distributed state problem that people are most familiar with. Anyone who has dealt with any large scale, high availability, or high performance piece of the problem knows that state is hell because they’ve lived with that hell. So the question is, “Why have more hell than you need to have?” You have to try and avoid it. Avoid. Avoid. Avoid.
vmstat是一个很全面的性能分析工具,可以观察到系统的进程 状态、内存使用、虚拟内存使用、磁盘的 IO、中断、上下问切 换、CPU使用等。系统性能分析工具中,我使用最多的是这个,除了 sysstat 工具包外,这个工具能查看的系统资源最多。对于 Linux 的性能分析,100%理解 vmstat 输出内容的含义, 那你对系统性能分析的能力就算是基本掌握了。我这里主要说明一下这个命令显示出的部分数据代表的含义,和 它反映出系统相关资源的状况。输出内容共有 6 类,分别说明如下。

r运行的和等待(CPU时间片)运行的进程数, 这个值也可以判断是否需要增加CPU(长期大于1)
b处于不可中断状态的进程数,常见的情况 是由IO引起的
内存够用的时候,这2个值都是0,如果这2个值长期 大于0时,系统性能会受到影响。磁盘IO和CPU资 源都会被消耗。我发现有些朋友看到空闲内存(free)很少或接近于0 时,就认为内存不够用了,实际上不能光看这一点 的,还要结合si,so, 如果free很少,但是si,so也很 少(大多时候是0),那么不用担心,系统性能这时 不会受到影响的。
随机磁盘读写的时候,这2个值越大(如超出1M),能看到CPU在IO等待的值也会越大
这个vmstat的输出那些信息值得关注
之前在系统中有做一个在客户端重试时,进行去重的逻辑,大致思路是将客户端的请求缓存到分布式缓存中,每次请求到达时先在缓存中查询,如果有就直接返回,没有就帮用户重试该请求。一天晚上(不凑巧,刚好是结婚当天),一个微信会话来了,某某老大的评论重复……
上面在写数据前,会先请求一次缓存,但是这个操作在分布式环境下显然会有如下场景出现:
① 节点A,Get数据,返回不存在
② 节点B,Get数据,返回不存在
③ 节点A写数据
④ 节点A返回
⑤ 节点B写数据
⑥ 节点B返回
根本原因就是Get数据和Set数据不是原子操作,导致出现了A,B都认为数据不存在。
问题很明显,就是没有对数据操作进行同步,如果在单机环境下,这个可以很简单的通过操作系统提供的各种同步原语处理,但是现在节点A,B是处在不同机器上,这就涉及到分布式锁的问题了。类似于单机环境下的线程同步原语,我们只需要一种机制让应用程序知道某个资源被占用了(例如mutex如果lock失败,操作系统即会将该进程挂起),在分布式缓存中一般都存在一个叫做add的操作,该操作保证只有在资源不存在时才能执行成功,否则会告知调用者失败,且标注为特殊的错误码。
这里只简单给出了获取锁一般实现伪代码,不同的业务场景有不同的处理,比如失败后继续重试直到成功。
在memcache中:
if(cache->add(key, value, expire))
{
//get lock successful
}
else
{
//get lock fail
}
SET key value NX EX max_lock_time。在redis-py中有一个封装好的lock实现可以直接使用。
像memcache,redis这里系统一般都是作为缓存来使用,但是在某些时候通过深入挖掘其实也可以有一些意想不到的作用,通过一个简单的语句既可以实现一个基本上够用的分布式锁,其性价比不言而喻。在网上随便一搜,也有好多类似的同行遇到这个问题,下面是几个链接,有国产的也有国外:
http://abhinavsingh.com/blog/2009/12/how-to-use-locks-for-assuring-atomic-operation-in-memcached/
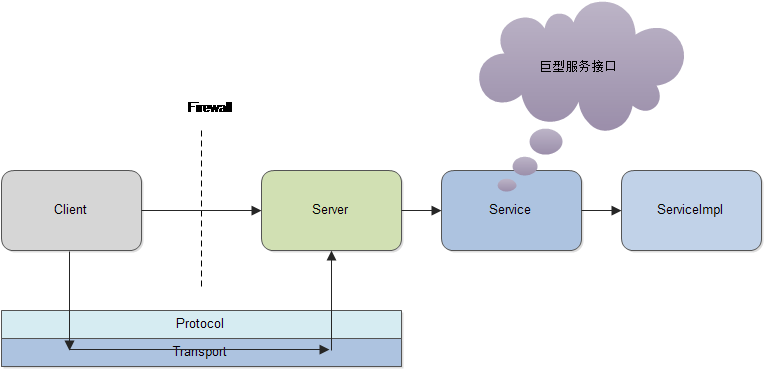
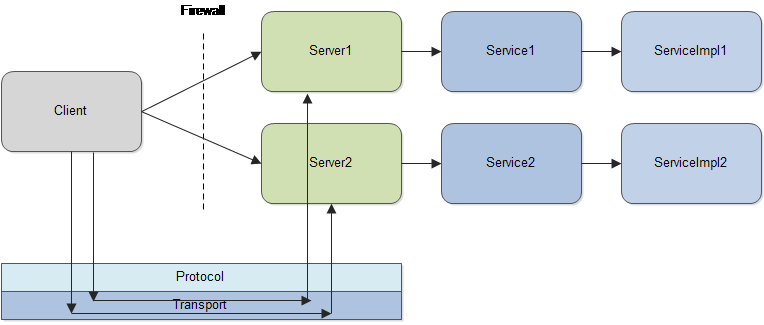

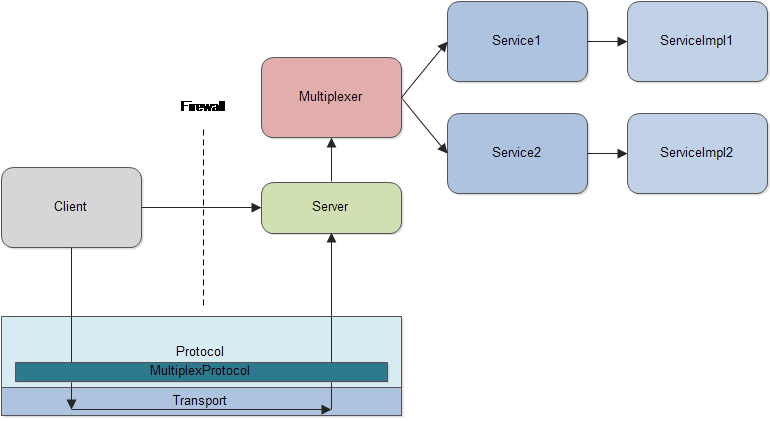
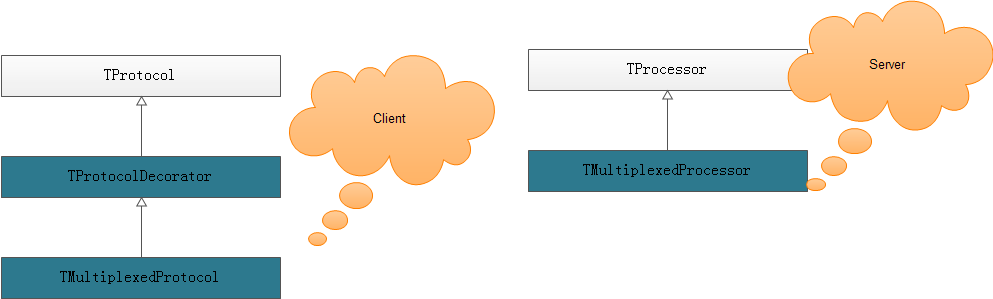
namespace cpp thrift.multiplex.demo
service FirstService
{
void blahBlah()
}
service SecondService
{
void blahBlah()
}
int port = 9090;
shared_ptr<TProcessor> processor1(new FirstServiceProcessor
(shared_ptr<FirstServiceHandler>(new FirstServiceHandler())));
shared_ptr<TProcessor> processor2(new SecondServiceProcessor
(shared_ptr<SecondServiceHandler>(new SecondServiceHandler())));
//使用MultiplexedProcessor
shared_ptr<TMultiplexedProcessor> processor(new TMultiplexedProcessor());
//注册各自的Service
processor->registerProcessor(“FirstService”, processor1);
processor->registerProcessor(“SecondService”, processor2);
shared_ptr<TServerTransport> serverTransport(new TServerSocket(port));
shared_ptr<TTransportFactory> transportFactory(new TBufferedTransportFactory());
shared_ptr<TProtocolFactory> protocolFactory(new TBinaryProtocolFactory());
TSimpleServer server(processor, serverTransport, transportFactory, protocolFactory);
server.serve();
shared_ptr<TSocket> transport(new TSocket(“localhost”, 9090));
transport->open();
shared_ptr<TBinaryProtocol> protocol(new TBinaryProtocol(transport));
shared_ptr<TMultiplexedProtocol> mp1(new TMultiplexedProtocol(protocol, “FirstService”));
shared_ptr<FirstServiceClient> service1(new FirstServiceClient(mp1));
shared_ptr<TMultiplexedProtocol> mp2(new TMultiplexedProtocol(protocol, “SecondService”));
shared_ptr<SecondServiceClient> service2(new SecondServiceClient(mp2));
service1->blahBlah();
service2->blahBlah();
今天听了QZone说说部分的架构分享,是这个系列分享迄今为止干货最多的一次,分享者讲得比较快,但是都很实在,个人觉得主要有以下几点值得学习:
近两年开始完全转向后台相关开发后,接触了不少开源软件,学习和使用优秀的开源软件不仅是对自己技术方面的提升,更能直接的获得不少物质上的收益,下面是我目前总结的两个途径:
写书
展开来讲,跟开源软件相关的书籍主要有两类:
目前知道的有以下几类:
今天把用了三年多的xp换成了win7,有很多软件是不需要重装的,但是vmware必须得重装,接踵而至的就是vmware虚拟的IP段和网卡地址变化,导致打开原有的虚拟机时会提示类似“I copy it or move it”。
这个应该是因为vmware网卡变化导致的,网上有找到这个copy和move的区别:
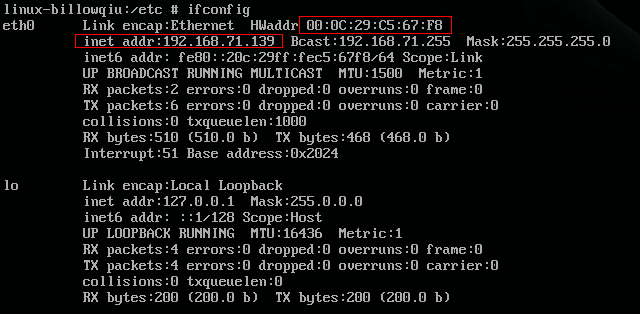
而重装后vmware的IP地址发生了变化: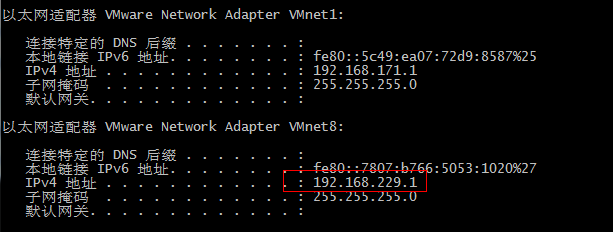 这就导致打开的虚拟机IP段和vmware的不匹配,从而无法与vmware通信,进而与本机实体机通信,最简单的临时方案时先在vmware中登陆,修改虚拟机的IP:
这就导致打开的虚拟机IP段和vmware的不匹配,从而无法与vmware通信,进而与本机实体机通信,最简单的临时方案时先在vmware中登陆,修改虚拟机的IP: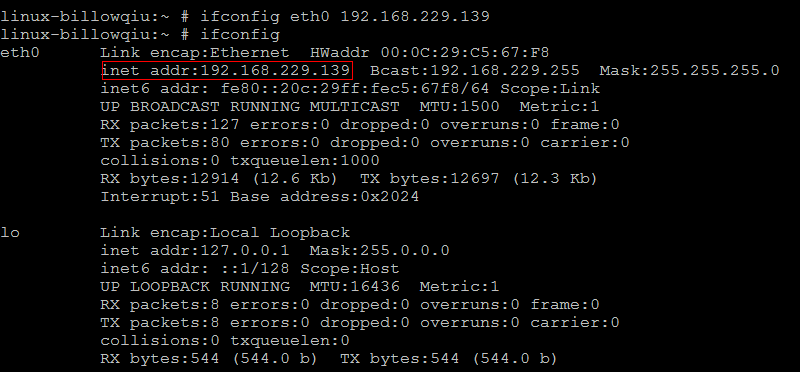
后面就可以通过secretcrt之类工具在windows使用了,但是每次都这样改也不是长久之计,终极方案是彻底修改掉其IP,在suse下面是如下文件:
/etc/sysconfig/network/ifcfg-eth-id-00:0c:29:c5:67:f8(后面这串数字其实就是虚拟机的mac)
修改后直接重启即可。
如果选择copy,好像是会改变网络接口名,也就是这个eth0,eth1,在/etc/udev/rules.d/30-net_persistent_names.rules文件中有如下记录:

http://gcc.gnu.org/install/这个是官方安装指导,比较全面,在网上看到一些方法大都不用这么复杂。下面记录一下前两天在我的CentOS 6.2上面的升级记录:
1下载安装包,包括gmp-4.3.2.tar.bz2,mpfr-2.4.2.tar.bz2,mpc-0.8.1.tar.gz,gcc-4.7.2.tar.bz2
2由于安装包之间有依赖关系,必须依次安装,步骤为
ln -s /usr/local/gcc/bin/gcc /usr/bin/gcc
ln -s /usr/local/gcc/bin/g++ /usr/bin/g++
另外如果可以上网的话可以按照这篇文字的介绍安装(没有实测过,应该是可以的)
http://www.cnblogs.com/linbc/archive/2012/08/03/2621169.html
2013.10.17更新:
遇到/usr/lib/libstdc++.so.6: version `GLIBCXX_3.4.15’ not found问题,主要是没有将相应的库更新,在gcc源码目录里面找到最新的库,gcc-4.7.2里面最新的是libstdc++.so.6.0.17,将其拷贝到/usr/lib/目录下面,删除原有链接,新建链接即可:
rm -rf `/usr/lib/libstdcln -s `/usr/lib/libstdc++.so.6.0.17/usr/lib64/libstdcexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/mpc/lib:/usr/local/gmp/lib:/usr/local/mpfr/lib/