当了好几年码工了,用得最多的IDE是VS,主要是配合助手实在是太强大了,偶尔也用用vim,eclipse,cb等工具,一直都觉得vs没有一个可以导入文件系统的方式创建工程很坑爹,这两天和同事交流才发现是自己一直都没有注意,vs(除了6)系列一直都有,且看下图(wordpress不能显示中文文件名的图?):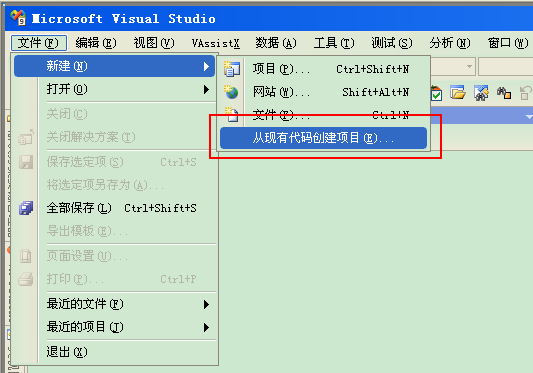
vim小技巧
由于最近工作代码量不会太多,打算用vim搞定,刚好弥补下之前vim囫囵吞枣式的使用习惯。
- ctags -R –languages=c,c++ .会生成一个tags文件,打开vim通过set tags=tags;命令设置tags文件路径,开始的tags表示会从当前目录找tags文件,分号后面可以再加其他可选的tags文件,ctrl+]在实现和定义之间跳转,ctrl+t回到上一个动作。
- Texplore这个命令可以在打开tab页时浏览文件夹,很方便的打开多个文件,剩下的就可以通过tab*命令切换tab页了
- %进行括号匹配跳转
- 可视化模型下,<,>分别进行减少,增加缩进
- set encoding设置文件在终端上面显示的编码
- set fileencoding设置文件写入磁盘的编码
XML,JSON然后呢
Data representation, a seemingly simple problem, is proving intractable as one standard after another fails to deliver what is needed.
- 二进制
- ASN.1
- XDR
- XML
- JSON/BSON
- TOML
- YAML(Ain’t Markup Language)
YAML看起来会火一阵子,等待下一个新的格式出现,BG好像对YAML使用比较多
http://www.drdobbs.com/web-development/after-xml-json-then-what/240151851
IT牛人博客
原文链接:http://blog.csdn.net/huang_xw/article/details/7957908
团队技术博客
- 淘宝UED淘宝用户体验团队
- 淘宝核心系统淘宝核心系统团队博客
- 阿里巴巴数据库团队专注数据库管理开发运维
- 淘宝通用产品专注JAVA技术
- 淘宝QA致力于做测试的行业标准
- 淘宝搜索技术关注技术 关注搜索
- 量子恒道专注大数据统计
- 百度搜索研发关注搜索相关技术
- EMC中国研究院关注于云计算和大数据
- 贰号楼肆层阿里巴巴平台技术部
- 阿里数据平台阿里巴巴数据平台
- 百度技术分享交流百度的互联网技术
- 编码者说腾讯滴技术团队
- 腾讯SOSOSOSO团队博客
- 人人网FED关注前端技术
- 阿里DBA Team阿里巴巴数据库团队
腾讯CDC为用户创造优质在线生活体验
底层架构博客邓侃移动互联网围观者,起哄者
- 杨建新浪架构师
- 陈臻米聊开发经理,54chen
- 阳振坤专注云计算和海量数据库
- 曹政4399架构师
- 陈皓酷壳博主
- 林仕鼎百度架构师
- 余锋Erlang系统深度探索和应用
- 王波百度十年码工
- 朱照远他就是淘叔度
- 刘炜他就是淘宝雕梁
- 吴镝专注基础架构,分布式系统
- 张宴Nginx大神
- 章文嵩LVS作者
- 李飞勃非主流程序员,呵呵
- 颜开在EMC
- 林晓斌他就是淘宝丁奇
- 阿稳豆瓣的算法攻城师
- RednaxelaFX曾经的淘撒迦
- Claymore通才啊
- Martin FowlerOO,CI泰山北斗
- TimYang新浪微博滴牛X人
- 王旭Cassandra权威指南译者
- 放翁 文初淘宝开放平台技术产品负责人
- 庆亮高性能服务端架构与设计
- 淘宝华庭Glibc内存管理
- 网易汪源网易杭州研究院副总监
- 黄亮关注企业存储、服务器相关
- 唐福林新浪微博开放平台架构师
- 孙立去哪儿网架构师
- 付超群搜索和数据挖掘的LAMP人
- 叶茂盛专注系统管理
- 潘少宁腾讯滴LAMP人
- 黑夜路人百度码农,很多有用博文
- 和煦主要研究开源程序
- 冯大辉UNIX,DB,WEB
- 宁海元一淘无线事业部高级技术专家
- 陈冠诚关注并行计算
王聪关注Linux Kernel
数据存储相关博客楊廷琨Oracle大牛
- 朱旭淘宝滴DBA
- 周振兴专注MySQL
- 朱龙春资深应用系统架构师
- 黄凯耀OS与Oracle牛人
- 盖国强Oracle ACE总监
- 黄忠支付宝滴资深DBA
- 童家旺DB神人
老熊Oracle/UNIX/数据恢复
语言开发惠新宸他就是鸟哥
- 闫斌PHP高手
- 黄毅Java传教士
- 温少做Java和.NET
- 陈硕muduo网络库作者
- 张善友多年的微软MVP
- 云风Lua大牛
- 刘未鹏C++罗浮宫
Solrex YangGDB高手
前端开发前端观察资讯,资源,技术
CSS森林腾讯滴,不知道离职了没
其他博客EssaysPaul Graham文集
- 阮一峰IT知名博客
- 对牛弹琴IT知名博客keso
- 月光博客关注互联网与搜索引擎
- Mr.6(台湾)网络趋势行销与开发
- 王建硕百姓网CEO
- 纯银网易产品总监
- 人人都是产品经理专注PM的知名博客
- 许晓斌Maven专家
- 范凯ITeye老大
- 白鸦UCDChina发起人
- 周金根敏捷个人创立和推广者
- matrix67神牛,不解释
- 余洪春构建高可用Linux服务器作者
- 阿朱《走出软件作坊》作者
- 徐宥Google的软件工程师
- vgodMIT的博士
- 阅微堂数学、金融、计算机
- 刘洋以老大自居的人,呵呵
linux线程死锁检测
代码中引用了libhdfs,在Hadoop集群负载过高或者某个datanode掉线死极易导致进程挂起,从堆栈可以看出是挂在了pthread_cond_timedwait上面而且是在libjvm.so附近,在https://svn.apache.org/repos/asf/hadoop/common/branches/HDFS-326/CHANGES.txt中有提到修复了一个deadlock的bug。
在目前这种过渡阶段也没有想到很好的办法去验证并修复这个问题,下面是我采取的一个简单方法,在程序中定时去touch一个文件,另外一个监控脚本去stat该文件的修改时间,如果时间超过一定范围即认为死锁了,kill -9然后拉起。但是在某些时候进程负载较高时会导致定时器没有被触发,这时监控脚本就会产生误杀现象。为了解决这个误杀,我又自作聪明的开了一个线程专门去定时touch文件,没过多久死锁现象又出现了,但是进程却没被kill,跟一个同事讨论后才意识到自己犯了一个很荒唐的错误,这里的死锁只是线程级别的!!!
后来另一同事共享了他的方案,通过pstack查看线程堆栈,如果一段时间内堆栈没有发生改变,那么进程基本上是死锁了,感觉这个方法也不错,但是程序中如果有多个线程也不太凑效。
linux设置DNS客户端
1修改/etc/resolv.conf,添加对应的nameserver和domain
2修改/etc/nsswitch.conf,找到hosts,在后面添加dns,即hosts: files dns,表示先从/etc/hosts文件查找,再通过dns查找
3重启dns cache进程nscd,否则可能会出现域名可以解析,但是ping不通
一个socket选项导致服务不可用
“All TCP servers should specify this socket option to allow the server to be restarted in this situation.”
最近为了提高机器利用率,将原来一台机器部署一个进程改为部署两个进程,考虑到运维的成本,就简单修改可以自动尝试新的端口,当时觉得这个只会在第二个进程启动时会出现。新版本发布没多久,通过网管系统发现异常了,到机器上一看,发现本该监听10086,10087两个端口的,结果变成了10088,10089,这尼玛肿么回事。通过监控脚本日志发现进程重启过了,按理说进程重启这端口还是不会变啊,查看运行日志发现进程重启时10086,10087都被占用了,通过netstat看到在10086上面有TIME_WAIT的链接,行家一眼就看出问题了,这尼玛不就是没设SO_REUSEADDR么,是的确实是通过设置了这个选项就搞定了。
这里顺便说下为啥端口变了就导致服务不可用,因为对外服务时是直接给的服务的指定端口,要是有一个配置中心之类的服务而不是直接暴露服务会更好些,这样就无所谓你端口变不变了,反正对外是透明的。
另外进程重启是因为在某些时刻进程负载过高导致定时器没有触发,间接导致监控脚本认为进程僵死而将其kill掉,这一点目前也修复了。
之前单进程部署时进程有时也会有重启现象,但是由于是非10086端口不可,因此在2MSL时间过后进程还是可以顺利启动的,当然之前没有防止进程僵死的监控,进程重启的概率非常小。
总结几点:
1UNP不仔细看完并实践,真不能写出健壮的网络程序
2当服务需要横向扩展时,提供一个类似配置中心的角色是必须的
架构设计需要考虑的非功能性需求
看了一些架构相关的资料,在讲非功能性需求时大部分都会提到以下几个词:
Reliability(可靠性)
Availability(可用性)
Scalability(伸缩性),包括水平和垂直两类,水平是指通过添加机器提高伸缩能力,垂直是指通过增加单机的硬件配置提高伸缩能力,显然单机的硬件配置是有上限的,因此水平伸缩才是王道。要做到水平伸缩可以通过以下方式进行:
- Load Balancing(负载均衡)
- Caching(缓存)
- Off-Line Processing(离线处理),也可以认为是异步处理,
- Partition by Function(按功能切分)这一点有点像公司那门海量课程<大系统小做>,数据层也可以按这个方式进行分离,比如典型的分库分表。
Resiliency(弹性)
mongodb分片配置
mongodb分片配置包括以下几个角色:
1configsvr,顾名思义就是存储配置的,这里的配置包括集群中的shareds,databases,collections等,
2shard,存放实际数据的进程
3mongos,路由进程
configsvr其实就是对应的mongod –configsvr,shard其实就是mongod –shardsvr
这里我搭建一个windows最简单的分片集群,所有进程都部署在同一台机器上。
依次执行如下命令,所以的dbpath可以随意指定,但是需要提前创建好:
binmongod –configsvr –dbpath data-config –journal –rest
binmongos –configdb 127.0.0.1:27019
正常启动后配置服务器会创建一个叫做”config”的数据库,包括如下集合:
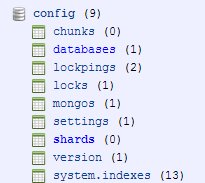
其中databases表示当前集群中的数据库信息,mongos即路由进程,shards目前还没有。
接着启动shard,依次执行如下命令,启动两个shards。
binmongod –shardsvr –dbpath data-shard1 –port 10086 –journal –rest
binmongod –shardsvr –dbpath data-shard2 –port 10096 –journal –rest
不出意外所以进程都会顺利启动,这时一个简答的分片集群就完成了一半了,剩下的就是将shards加入集群,这需要通过mongo shell来完成。
启动binmongo 127.0.0.1:27017/admin,这里ip:port是mongs的,admin是默认的管理数据库,执行如下命令:
sh.addShard(“127.0.0.1:10086”)
sh.addShard(“127.0.0.1:10096”)
此时config数据库中的shards集合数变为2,文档内容如下:
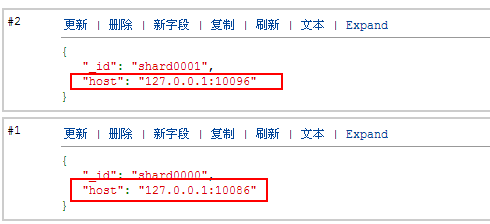
至此一个简单的分片集群即搭建完毕,接下来往里面搞点数据。
- 指定可以分片的数据库
- 指定可分片的集合
- 插入数据
sh.enableSharding(“billowqiu”),表示”billowqiu”这个数据库需要分片;
sh.shardCollection(“billowqiu.education”, {“date”:1}),表示eduction这个集合按照{“date”:1}的shard-key方式进行分片,这里的shard-key是必须要的,关于shard-key-pattern的详细信息可以去mongo官网查看。
插入数据的方式和普通模式类似,唯一需要注意的是插入时必须带上shard-key,例如
use billowqiu
col=db[“education”]
col.insert({“date”:1997} ,{“name”:”taer mid school”})
col.insert({“date”:2000} ,{“name”:”huangpi three high school”})
总的来说,mongodb配置和使用都是比较容易上手的,其分片模型和许多Master-Slave模式类似,只不过多了一个configsvr的角色,像gfs,bigtable中这些分布式系统中master的角色其实包括了config和mongos。